Abstract
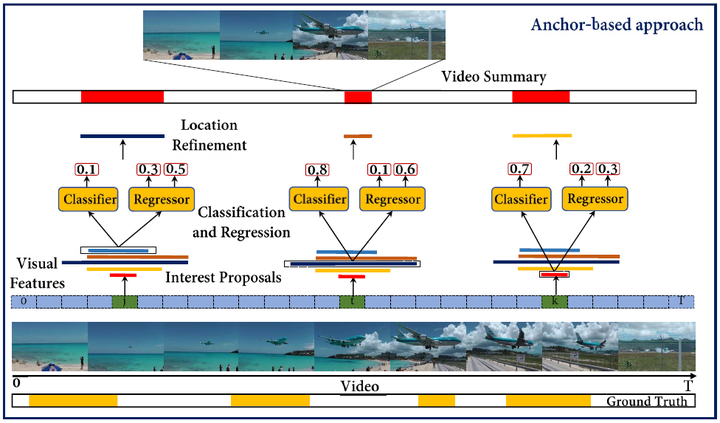
In this paper, we propose a Detect-to-Summarize network (DSNet) framework for supervised video summarization. Our DSNet contains anchor-based and anchor-free counterparts. The anchor-based method generates temporal interest proposals to determine and localize the representative contents of video sequences, while the anchor-free method eliminates the pre-defined temporal proposals and directly predicts the importance scores and segment locations. Different from existing supervised video summarization methods which formulate video summarization as a regression problem without temporal consistency and integrity constraints, our interest detection framework is the first attempt to leverage temporal consistency via the temporal interest detection formulation. Specifically, in the anchor-based approach, we first provide a dense sampling of temporal interest proposals with multi-scale intervals that accommodate interest variations in length, and then extract their long-range temporal features for interest proposal location regression and importance prediction. Notably, positive and negative segments are both assigned for the correctness and completeness information of the generated summaries. In the anchor-free approach, we alleviate drawbacks of temporal proposals by directly predicting importance scores of video frames and segment locations. Particularly, the interest detection framework can be flexibly plugged into off-the-shelf supervised video summarization methods. We evaluate the anchor-based and anchor-free approaches on the SumMe and TVSum datasets. Experimental results clearly validate the effectiveness of the anchor-based and anchor-free approaches.
Jiahao Li
Senior student of Tsinghua University
I am focusing on computer architecture and machine learning infrastructure.