Abstract
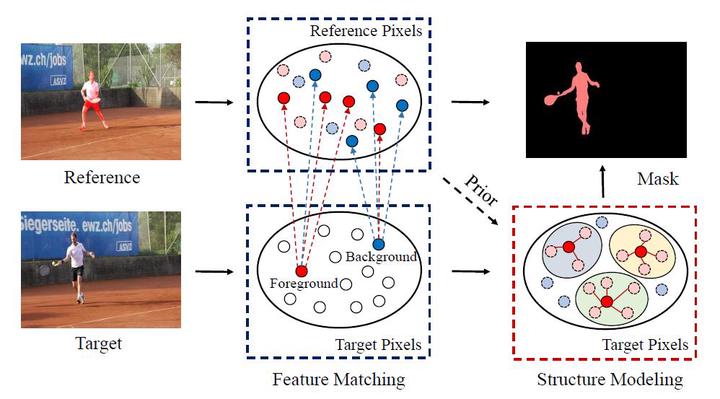
In this paper, we propose a separable structure modeling approach for semi-supervised video object segmentation. Unlike most existing methods which preclude the semantically structural information of target objects, our method not only captures pixel-level similarity relationships between the reference and target frames but also reveals the separable structure of the specified objects in target frames. Specifically, we first compute a pixel-wise similarity matrix by using representations of reference and target pixels and then select top rank reference pixels for target pixel classification. According to the prior knowledge from these top-rank reference pixels, we further appoint the representative target pixels for object structure modeling. Particularly, in the structure modeling branch, we extract the shared and individual features that can well represent the whole object and its components, respectively. Moreover, the proposed method is a fast algorithm without online fine-tuning and any post-processing. We conduct extensive experiments and ablation studies on the DAVIS-16, DAVIS-17, and YouTube-VOS datasets, and experimental results on three widely-used datasets demonstrate that our method achieves a superior performance, compared with state-of-the-art semi-supervised video object segmentation approaches in terms of speed and accuracy.
Jiahao Li
Senior student of Tsinghua University
I am focusing on computer architecture and machine learning infrastructure.